正则表达式应用“如何判断字符串中不包含连续重复的数字或者字母”
正则表达式是用来查找、判断、替换字符串的一类工具。是很有意思的内容。很多编程语言都支持正则表达式,而且使用形式都大同小异。
今天来判断的情况是字符串中不包含连续重复的数字或者字母,比如:
aaaa,1111,abcccc111,qqqwww,qweeeeerty,等等。
前置知识:如何学习正则
这篇文章的内容需要有正则表达式的知识,如果没学过正则表达式的同学,可以看一下这个教程,我觉得写的很好:
正则表达式用来测试也非常简单,直接打开浏览器的console界面,用Javascript测试即可: 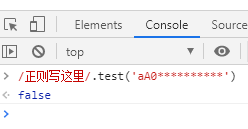
用Javascript测试只需要掌握几个函数的用法,看这个教程就可以:
https://www.runoob.com/js/js-regexp.html
下面,我们从零开始,一步一步实现我们的目标“判断字符串中不包含连续的数字或者字母”。
如何判断字符串中包含连续重复的数字或者字母?
首先是表示出任意一个数字或者字母:
[a-zA-Z0-9]或者直接\w也可以。
然后用括号括起来,让它成为一个分组:
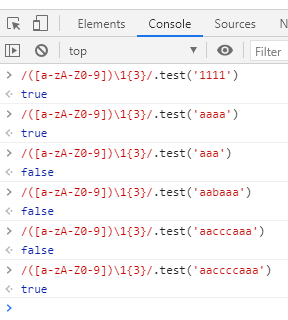
([a-zA-Z0-9])然后再把这个分组重复3次(加上原来的一共四次):
([a-zA-Z0-9])\1{3}现在就可以检测重复4次的数字或者字母了:
上面的正则中。\1表示第一个分组。但是之后正则表达式会越来越长,还会有嵌套的分组,到时候找到分组的序号可能比较困难,因此我们改为了命名分组:
(?<re1>[a-zA-Z0-9])\k<re1>{3}现在,我们就实现了判断字符串中包含连续的数字或者字母这个功能了。
如何判断字符串中不包含连续重复的数字或者字母?
上面说了包含,那么怎么判断不包含呢?
最简单的方法当然是:
!(/(?<re1>[a-zA-Z0-9])\k<re1>{3}/.test('aacccaaa'))先用上一节的方法判断包含,然后再取反就好了。
简单的应用当然可以这样做,但是如果这部分正则表达式是一个大的正则表达式的一部分呢?比如要给一个判断密码是否符合规范的正则表达式中添加”判断不包含连续重复的数字或者字母”功能呢?这时候就没办法用取反了,毕竟正则表达式基本不支持逻辑运算。因此,我们还是用正则来实现这个功能。
实现这个功能,而且还不影响正则表达式其他部分的匹配,我们要用到负向零宽断言。
首先来加一个负向零宽先行断言:
(?!(?<re1>[a-zA-Z0-9])\k<re1>{3})测试一下效果: 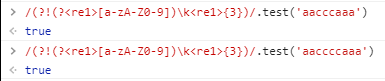
不管用了!不管有没有重复的字符,都显示true。
再试试负向零宽后行断言:
(?<!(?<re1>[a-zA-Z0-9])\k<re1>{3})经过测试也不行。
一个先行,一个后行,是不是需要组合起来?
(?!(?<re1>[a-zA-Z0-9])\k<re1>{3})(?<!(?<re2>[a-zA-Z0-9])\k<re2>{3})(注意不同的分组名称不一样哦)
可以了? 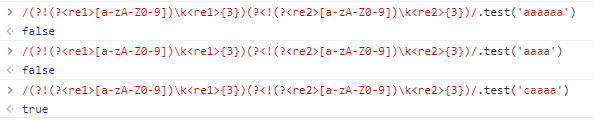
从这个结果来看,看起来只能判断字符串开头是重复的情况。
如果要任意位置都能判断呢?加入标识任意位置符号“.*”就好了。
(?!.*(?<re1>[a-zA-Z0-9])\k<re1>{3})(?<!.*(?<re2>[a-zA-Z0-9])\k<re2>{3})测试结果如下: 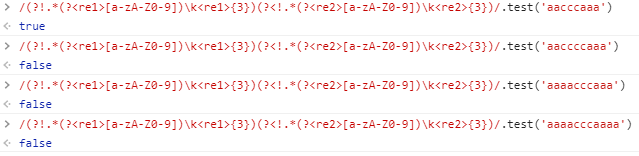 看来是正确的。
看来是正确的。
这样就实现了,不管在任意的位置,前面和后面都不能出现连续重复至少4个的字母或者数字。
扩展,可继续包含其他条件
在这个正则中我们还可以继续包含其他的判断条件,比如必须包含abc:  还可以把这个”必须包含abc”的条件写成零宽断言的形式,同学们可以自己试一试。
还可以把这个”必须包含abc”的条件写成零宽断言的形式,同学们可以自己试一试。